批处理命令设置环境变量
set path=xxxx
好玩的东西
Lambda 递归
1 | f = (lambda h: lambda n:(h(h, n)))(lambda f,n: n + f(f, n-1) if n > 0 else 0) |
Lambda 计数器
1 | f,n = (lambda f,n=0: ((lambda f, n: lambda x, m=n: f(x, m))(f, n+1), n))(lambda f,n: ((lambda f, n: lambda x, m=n: f(x, m))(f, n+1), n)) |
更好玩的版本!
1 | f,n = (lambda f,n=0: ((lambda h: lambda: h(h))((lambda f, n: lambda x, m=n: f(x, m))(f, n+1)), n))(lambda f,n: ((lambda h: lambda: h(h))((lambda f, n: lambda x, m=n: f(x, m))(f, n+1)), n)) |
与上一个版本效果相同:
1 | f = (lambda g: g(lambda f,n=0: (g((lambda f, n: lambda x, m=n: f(x, m))(f, n+1)), n)))(lambda h: lambda: h(h)) |
更加简洁:
1 | f = (lambda g: g(lambda f,t, n=0: n if t == 0 else g((lambda f, t, n: lambda x, u=t, m=n: f(x, u, m))(f, t, n+1))))((lambda h: lambda t=1: h(h, t))) |
js爬虫
1.js保存字符串到本地
1 | function saveShareContent (content, fileName) { |
2. 包含iframe/#document的文档
1 | var ifram = document.querySelector("#iframe") |
层层剥开,否则在iframe内部的元素会定位失败。在F12界面右键选择“复制js路径”可以获取 querySeletor语句。
3.滚动至最低部
1 | var ele = document.documentElement; |
必要时可以增加 setTimeout等待网页加载完毕。
4.逐步滚动
1 | var count = 0; |
electron-vue
如何引入.node文件
需要将.node文件放在public文件夹下,引用时可以用相对路径也可以用 __static+文件名。
需要安装node-loader@1.0.3。太高的版本会导致问题。
1 | const addon = require("node-loader!../public/addon.node") |
在vue中使用ipcRenderer
主进程中引入ipcMain没啥大问题。
在vue文件中引入ipcRenderer,需要先在vue.config.js中配置
1 | nodeIntegration: true |
然后在各个vue文件中引入
1 | import { ipcRenderer } from 'electron' |
math
一个只跟a, b中最大的那一个有关的积分:
$$ \int_{0}^{\pi}\frac{\sin \theta}{\sqrt{a^2+b^2-2ab\cos\theta}}\mathrm d\theta = \frac{1}{ab}(|a+b| - |a-b|) $$js 小技巧
可变定时检测
问:每隔10秒检测一次当前页面是否包含某字符串,如果包含,则 console.log,下次检测的时间变为 100 秒
答:为了实现这个功能,你可以使用 setInterval函数来设置一个定期执行的任务。然而,因为你想在满足特定条件时改变间隔时间,你可能需要使用 setTimeout来代替,因为 setInterval的间隔时间一旦设定就无法改变。以下是如何实现这一逻辑的示例代码:
1 | function checkContentAndAdjustInterval(searchString, initialDelay, newDelay) { |
这段代码首先定义了一个 checkContentAndAdjustInterval函数,它接受三个参数:要搜索的字符串 searchString、初始的检查间隔时间 initialDelay(以毫秒为单位)、以及在找到字符串后新的检查间隔时间 newDelay。
在 checkContentAndAdjustInterval函数内部,定义了另一个名为 checkAndSchedule的函数。checkAndSchedule函数首先检查当前页面的内容是否包含指定的字符串。如果包含,它将使用 console.log输出一个消息,并使用新的延迟时间 newDelay来安排下一次执行。如果不包含指定的字符串,它将继续使用初始的延迟时间 initialDelay来安排下一次执行。
最后,checkContentAndAdjustInterval函数通过调用 setTimeout并传入 checkAndSchedule函数和初始延迟时间 initialDelay来启动整个检查流程。
这种方法的好处是你可以灵活地控制检查的间隔时间,而且它在满足特定条件后能够自动调整这个间隔,非常适合需要根据条件动态调整检查频率的场景。
NFS 常用指令
主要参考:如何在 Ubuntu 20.04 上安装和配置 NFS 服务器? - 知乎 (zhihu.com)
服务端绑定 NFS
直接绑定:
1 | sudo mount --bind /opt/backups /srv/nfs4/backups |
要在重新启动后使绑定挂载永久化,请打开/etc/fstab文件:
1 | sudo nano /etc/fstab |
并添加以下行:
1 | /etc/fstab |
/var/www 为本地需要绑定的文件夹,/srv/nfs4/www 为 NFS 管理的文件夹,必须以 /srv/nfs4开头。
绑定后,服务端可以修改 /var/www 内的文件,会被自动同步到 NFS 绑定的目录下。
客户端绑定 NFS
为挂载点创建两个新目录:
1 | sudo mkdir -p /backups |
您可以在任何您想要的位置创建目录。
使用以下命令挂载导出的文件系统mount :
1 | sudo mount -t nfs -o vers=4 192.168.33.10:/backups /backups |
要在重新启动时永久挂载,请打开/etc/fstab文件并添加以下行:
1 | sudo nano /etc/fstab |
有关挂载 NFS 文件系统时可用选项的信息,请输入man nfs您的终端。
IP 检测
编辑配置文件
1 | sudo nano /etc/exports |
配置文件例子:
1 | /srv/nfs4 192.168.33.0/24(rw,sync,no_subtree_check,crossmnt,fsid=0) |
其中,192.168.33.0/24 等为需要过滤的 ip 规则。
应用 ip 设置
1 | sudo exportfs -ar |
查看 ip 检测
1 | sudo exportfs -v |
重启 NFS
1 | sudo /etc/init.d/nfs-kernel-server restart |
WSL 相关
WSL 寄了!
可能是因为配置 nfs 的原因吧,wsl 关掉之后就打不开了。
- wsl 无响应。
- 当 ubuntu 处于停止状态时,
wsl --list,wsl --status有响应;但我一旦尝试运行wsl以启动 ubuntu,就无响应了。 wsl --help一直没问题。
怀疑是配置 /etc/fstab 的时候出的问题,导致 wsl 无响应。
后来的解决方案:
- 把
ext4.vhdx备份了一份。 - 卸载 ubuntu distro,重新安装了一遍 ubuntu 22.04。
wsl --mount --vhd将ext4.vhdx挂到新安装的 ubuntu wsl 上。
幸好 ext4.vhdx 还在。
另外,挂完 ext4.vhdx 后,我将存有 ext4.vhdx 的移动硬盘拔出,然后重新打开 wsl,发现出现了同样的问题。这样就验证了我的假说:
- 我设置了开机默认挂载 nfs 硬盘,连接远程的服务器。
- nfs 服务器因为一些原因没连上。
- wsl 文件系统因为挂载的硬盘找不到了,发生错误。
- wsl 在启动界面无响应。
重启了电脑,发现之前 wsl --mount 挂载的 ext4.vhdx 已经被清空了,证明 wsl –mount 命令的效果在重启之后清空了。
yarn add hasura-cli 安装失败
报错:
1 | Command: node dist/index.js |
解决方案:手动下载 hasura-cli 的二进制文件,并粘贴到 node_modules/hasura/。
SSH 相关
ssh 端口转发的坑点
转发之前一定要在远程服务器的 /etc/ssh/sshd_config 中配置:
GatewayPorts yes(或 clientspecified,不能是 no)
具体的原理我说不清楚。大概意思是,我们通常用以下方式进行远程端口转发:
1 | ssh -CNgv -R <remote_ip>:<port>:<local_ip>:<port> <hostname> |
一般会把 remote_ip 设为 0.0.0.0,以绑定到所有接口。但是,若不设置 GatewayPorts,则远程服务器上仍然只有 localhost 能够访问这个端口,如果你在 docker 容器内访问这个端口是不行的。我花了很多时间去排除 docker 容器到主机上的连接是否正确,包括使用 docker 的网关地址/host.docker.internal、修改 iptables、修改防火墙,都没什么用。因为实际上这个 ip 可以 ping 通,根本就不是 ip 地址或者防火墙的问题,是 ssh 转发里面限制了网关访问端口。
claude-sonnet 给出的解释如下:
| 配置选项 | 客户端命令 | 实际绑定地址 | 说明 |
|---|---|---|---|
no |
ssh -R 8000:... |
127.0.0.1:8000 |
强制 localhost |
no |
ssh -R 0.0.0.0:8000:... |
127.0.0.1:8000 |
忽略客户端指定 |
yes |
ssh -R 8000:... |
0.0.0.0:8000 |
默认所有接口 |
yes |
ssh -R 192.168.1.1:8000:... |
192.168.1.1:8000 |
允许指定 |
clientspecified |
ssh -R 8000:... |
127.0.0.1:8000 |
默认 localhost |
clientspecified |
ssh -R 0.0.0.0:8000:... |
0.0.0.0:8000 |
允许客户端指定 |
可以看到,如果服务端配置为 no,无论客户端怎么强制绑 0.0.0.0 都没用的,还是变成了 localhost:8000 的服务。如果设置为 yes,那么默认就绑 0.0.0.0:8000,要指定也是可以的。
服务器共用怎么设置自己的环境变量
在 vscode user settings 中添加:
1 | "terminal.integrated.env.linux": { |
在启动文件(例如 .bashrc)中添加:
1 | # used for zzz's bash init if the env var below is defined |
ssh 服务器
使用 ssh-keygen 时最好设置一个口令,否则别人也能用这个密钥。
常用命令
ssh 反向代理(服务器端口映射到本地端口),挂在后台
1 | ssh -CqTfnN -R <remote_port>:localhost:<local_port> -v username@hostname -p <ssh_port> |
ssh 前向代理(本地端口映射到服务器端口)
1 | ssh -CqTfnN -L <local_port>:localhost:<remote_port> -v username@hostname -p <ssh_port> |
将请求转发到 github
1 | ssh -CqTfnN -L <local_port>:github.com:22 -v username@hostname -p <ssh_port> |
ssh agent
启动 ssh agent,并查看 pid
1 | eval $(ssh-agent -s) |
查看当前 agent 有哪些密钥
1 | ssh-add -l # 查看公钥的 sha256 |
添加密钥
1 | ssh-add <private_key_path> |
Node.js
listen EACCES: permission denied 0.0.0.0:3000
1、先判断是否是端口占用的问题导致的 netstat -ano| findstr 3000
关闭相关进程(cmd)
1 | taskkill /PID <process_id> /F |
发现并没有程序在使用这个端口
2、改用管理员再运行一遍
发现仍然不行
3、使用管理员权限运行以下命令
net stop winnat
net start winnat
AI
Could not load symbol cudnnGetLibConfig
环境变量的问题,如果你在环境变量中将 LD_LIBRARY_PATH 指向了不正确的版本会导致这里出问题。
运行下面的代码以获得正确的 cudnn 路径:
1 | export LD_LIBRARY_PATH=`python3 -c 'import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__))'` |
/usr/bin/ld: cannot find -lcuda
export LIBRARY_PATH=”/usr/local/cuda/lib64/stubs:$LIBRARY_PATH”
export LD_LIBRARY_PATH=”/usr/local/cuda/lib64/stubs:/usr/local/cuda/lib64”
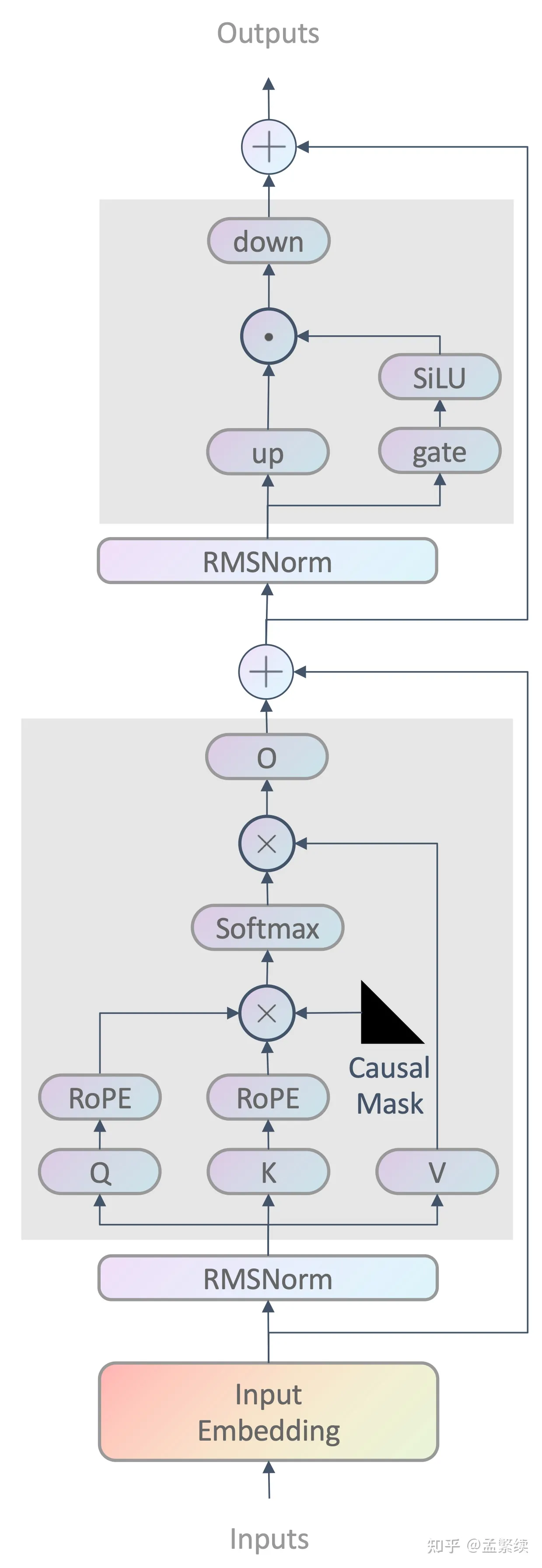
Llama 架构
使用 Tensorboard
1 | from torch.utils.tensorboard import SummaryWriter |
记录神经元的激活值
1 | from torch import nn |